

)










こんにちは、アウラ広報部です。すっかり秋も深まり、冷え込んできましたね。
今日はWebスクレイピングのツールをご紹介します。Webスクレイピングとは、データ解析を目的として、ショッピングサイトなどカタログ的な情報を含むサイトから、欲しいデータを自動的に収集することをいいます。
自作のプログラムで対応するかたもいらっしゃいますが、お手軽なウェブツールもいくつか世に出ています(ただ、日本語化されているものは見当たりませんでした)。今回は、その一つ dexi.io ( https://dexi.io/ )を使ってみましたので、簡単にその使い方を紹介したいと思います。
dexi.ioの特徴としては、ユーザの操作で画面の表示内容が変わる動的なページに対応している点、また直感的なインターフェイスのおかげでマニュアルをきちんと読まなくても試行錯誤のうちに使えるようになる(かもしれない)点が挙げられます。
サインアップはGoogle IDやGithub IDでも可能です。また、有料プランもありますが、無料のFree trialでも実行時間1時間まで使えます。
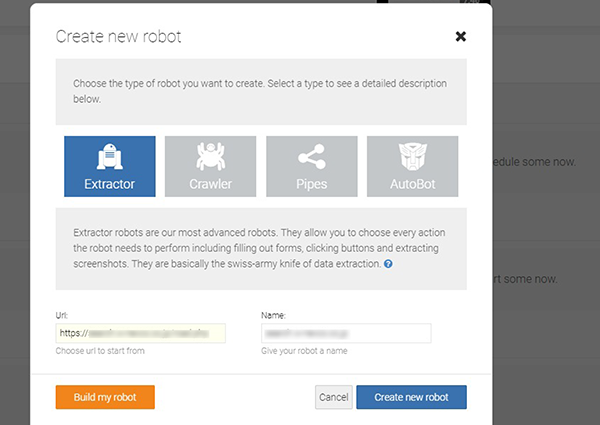
サインアップが済んだら、Dashboard 画面の右のほうにある緑色の [New robot] ボタンをクリックします。すると、「Create new robot」というタイトルの画面が開きます。ここで作成するロボットのタイプを選びます。R2-D2みたいなアイコンの [Extractor] (抽出プログラム)を選択。下のほうの「Url」欄には解析対象のURLを入力します。その右の「Name」は自動でサイト名が入りますのでそのままでよいでしょう。最後に、[Create new robot] をクリックします。
作業に入る前に、解析対象のサイトの構造を前もってブラウザのデベロッパー・ツールなどで調べておくとよいでしょう。今回、説明のための例として、セレクトボックス内をクリックして選択すると隣のテーブルの内容が変わるページを想定しています。以下にコード例を示します。ここで、html要素のID名に注目しておいてください (あとの説明に関係します)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
<select id="selectBox"> <option value="01">オプション01</option> <option value="02">オプション02</option> (中略) </select> <table id="dataTable"> <tr> <td>行1 列1 の項目</td> <td>行1 列2 の項目</td> </tr> <tr> <td>行2 列1 の項目</td> <td>行2 列2 の項目</td> </tr> (中略) </table> |
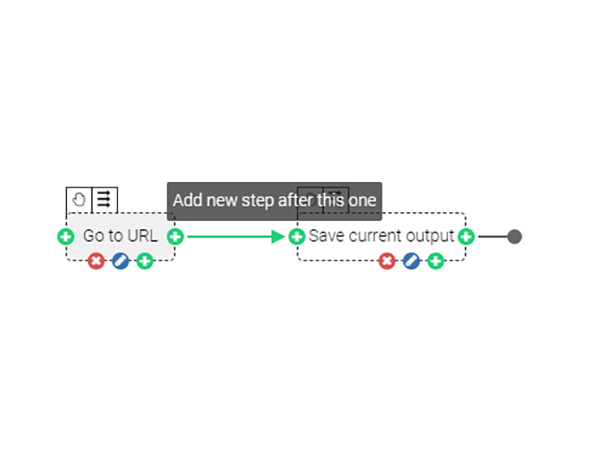
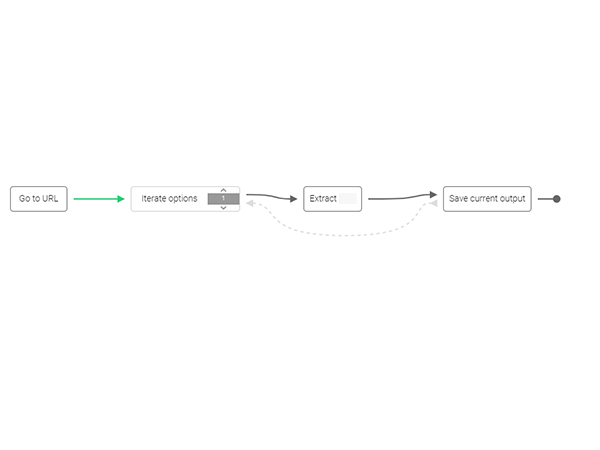
プログラムの作成画面が立ち上がると、画面は上下2段の構成になっています。上部に対象サイトのビューがあり、下部にはプログラムの各ステップを図示したもの(「Steps」のタブ)やコントローラが並んでいます。「Steps」では最初は、下図のように最初のステップ「Go to URL」と最後のステップ「Save current output」、2つのオブジェクトだけが表示されています。これから、これらのステップの間に新たなステップを順次追加していくことになります。
「Go to URL」のボックスにカーソルを持っていきます。すると周囲にいくつかアイコンが表示されます。右端の [+] のマーク (Add new step after this one) をクリックします。
すると、「Select an extractor step」というタイトルの、これから追加したいステップを選択するパネルが開きます。
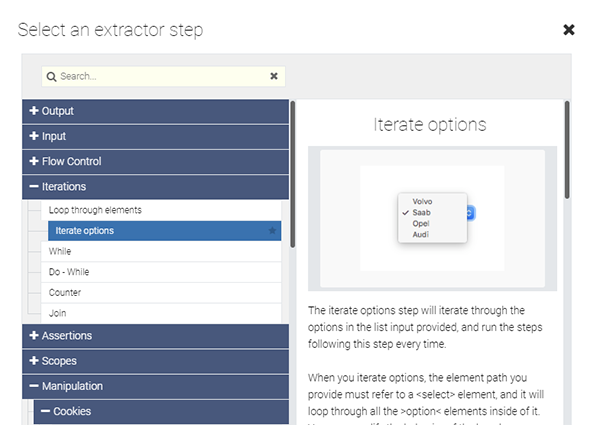
左の欄から、[Iterations] -> [Iterate options] を選択し、[OK] をクリックします。すると画面右下に「Add step after」というタイトルの詳細設定パネルが表示されます (画面は省略します)。その中の「Element paths」という入力欄に、以下のように該当するhtml要素を入力します。ここではcssセレクタの記法で指定します。 select#selectBox > option
なお、入力欄の左にあるダーツの的のような形のアイコンをクリックすることで、画面上部で要素を直接選択することもできますが、なかなか意図した通りに選択できないことが多いので直接セレクタで指定する方法をおすすめします。
次に、セレクトボックス内で選択中の項目の値を取得するステップを追加します。さきほどの操作で画面下部「Steps」に追加された「Iterate options」オブジェクトの右にある [+] をクリックします。今回は「Extract Value」を追加します。画面右下の詳細設定パネルの「Output field」欄の右に出てくる緑色の [+] マーク (Add output field) をクリックして、保存先のフィールド名(何でも構いません)を入力し(「New field name」欄)、タイプは Text (「New field type」欄) としてフィールドを作成します (画面は省略)。 Element paths には select#selectBox option:checkedとします。
ここまでの操作で、画面下部のステップ一覧は以下のようになっているとOKです。
ここからはテーブルの内容を取得する過程に移ります。これまでと同様に、さきほど作られたステップの右の [+] をクリックし、次のステップを指定します。今回は「Loop through elements」を選びます。「Element paths」は table#dataTable tr:nth-child(n+0) とします。
さらに、行ごとの値を取得するため、「Extract Value」を追加します。ここでも保存先として適当なフィールドを作成のうえ、指定しておきます。「Element paths」は、列1の項目がほしい場合 td:nth-child(1) 、列2の項目がほしい場合は td:nth-child(2) とします。これで完成です。
画面下部、右上のコントローラが並ぶ中に、音楽プレーヤの「再生」ボタンのような右向き三角のアイコンがあります。これをクリックすると、プログラムが実行されます。「Results」のタブをみると、データがどんどん出力されていくのがわかります。
いかがでしたでしょうか。dexi.ioは非常に使いやすいサービスだと思います。今回紹介したもの以外にも多くの機能がありますので、ご興味のあるかたはぜひいろいろ触ってみてください。
Webスクレイピングでは解析対象のサイトに過大な負荷をかけないことが必要です。dexi.ioで作成したものは、デフォルトの設定のままで、サーバに極端な負荷をかけないような動作の遅いプログラムになるので、その点は問題ないと思います。ただ、Twitterのように、動作スピードにかかわらずボット類の使用を規約で全面的に禁止しているサービスもありますので、その点はよくご確認のうえでご使用ください。




